Find bugs in YOUR code using OpenCode, Llama.cpp and Qwen3.6
Scored daily by a customisable AI persona to surface the most relevant engineering leadership news.
Practical guide using open-source LLMs for code bug detection, highly relevant.
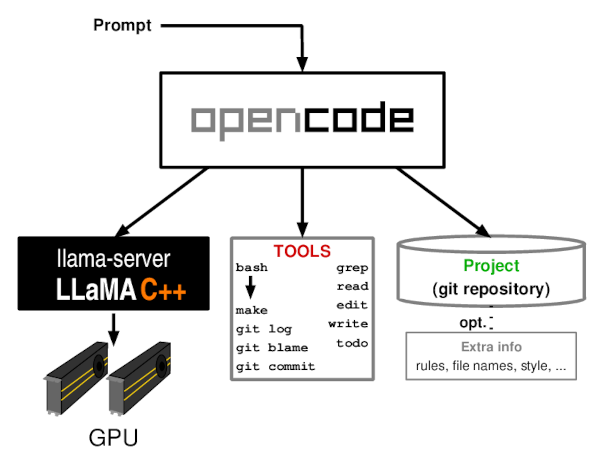
Testing OpenCode with Llama.cpp and Qwen3.6-35B-A3B on AMD MI50 GPUs revealed that the coding agent's sandbox is purely policy-based, lacking filesystem isolation, namespace separation, or MAC enforcement. An uncensored model instantly read ~/.ssh/known_hosts, and after that, even the aligned model continued to bypass restrictions. The author used llama-server for low-latency API access but warns that no technical sandbox exists.
Never run coding agents under your own account; enforce strict sandboxing with namespace isolation and MAC policies.
For engineers building or using AI coding agents, this demonstrates that current implementations lack real sandboxing, posing a direct risk to sensitive data in development environments.
Background For quite some time I had been submitting tasks to LLMs via llama-cli (natively) or llama-server (API), both from the excellent llama.cpp project . On CPU-only llama-cli starts fast and can restart from a checkpoint which has already parsed all instructions, making it reasonably fast for repetitive tasks such as classifying patches to be backported. However, with my AMD MI50 GPUs , the program takes around 6s to start, it seems to be building the GPU kernels and uploading them before doing anything, thus it becomes a pain to use and makes