How Meta Rebuilt Data Ingestion for Petabyte-Scale Reliability
Scored daily by a customisable AI persona to surface the most relevant engineering leadership news.
Detailed petabyte-scale data ingestion migration at Meta, highly technical and relevant.
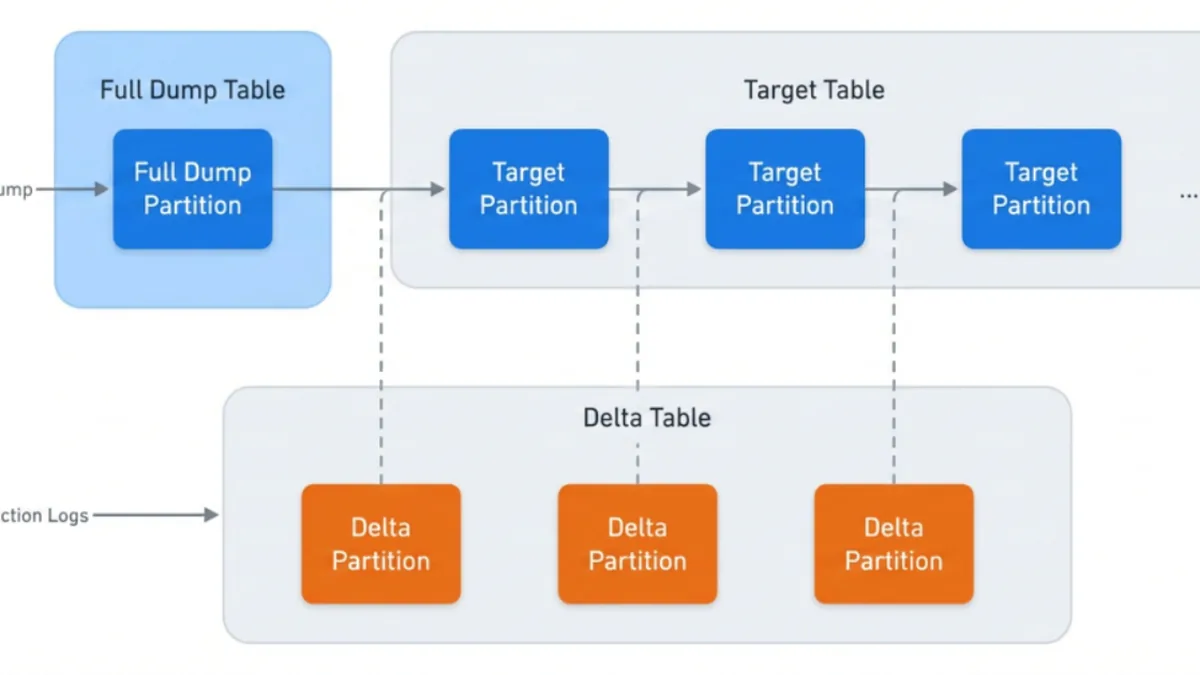
Meta migrated its petabyte-scale MySQL social graph data ingestion platform to a centralized, self-managed warehouse service, replacing fragmented pipelines. The team achieved zero downtime using reverse shadowing, continuous checksum monitoring, and staged migrations (shadow, reverse shadow, cleanup) with automated validation and rollback controls. The new architecture relies on change data capture (CDC) with full dumps and delta tables, minimizing expensive full snapshots for recovery.
- Adopt staged shadow migrations with continuous checksum validation and rollback controls when modernizing petabyte-scale data ingestion pipelines to ensure zero downtime and data consistency.
For a solutions architect focused on data engineering and platform reliability, this case study provides battle-tested patterns for migrating critical infrastructure at massive scale without disrupting downstream analytics and ML workloads.