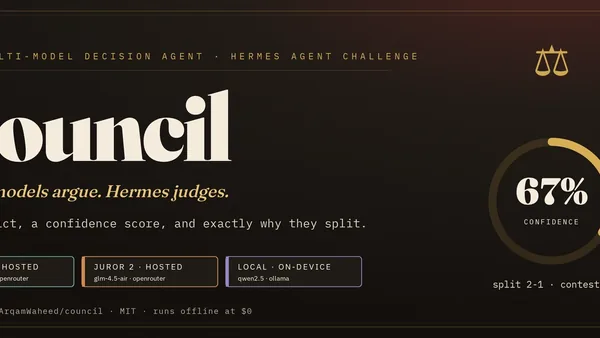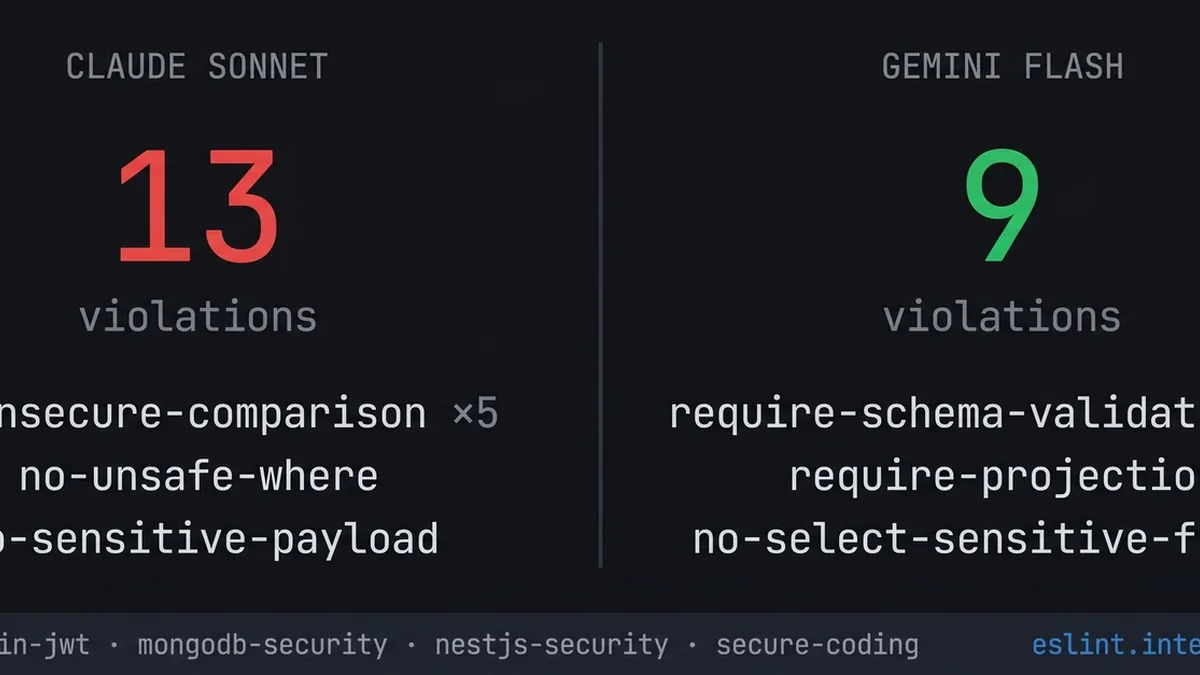
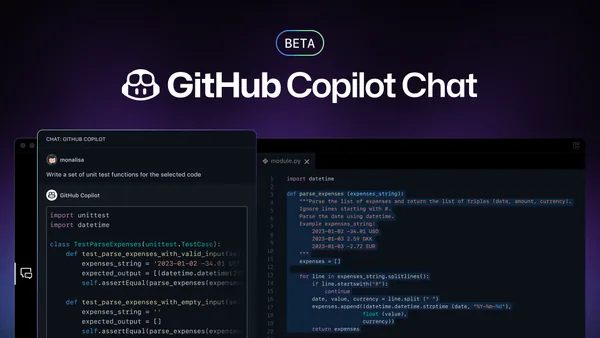
‘What a joke’: Github Copilot’s new token-based billing spurs consternation among devs
Microsoft's GitHub Copilot switches to token-based billing on June 1, with reported cost jumps from $29 to $750 and from $50 to $3,000 per month, drawing intense backlash from developers. Critics attribute excessive token consumption to 'vibe coding' practices, while others argue Microsoft encouraged heavy usage before changing the pricing model. The shift exposes the unsustainable economics of flat-rate AI coding assistance and creates budget uncertainty for small teams and individual developers.