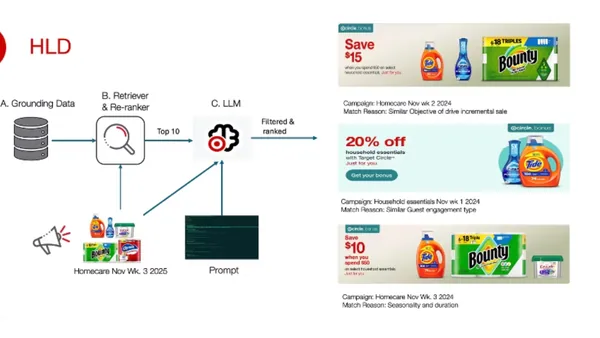
AGENTS.md: The One File That Makes AI Coding Agents Actually Useful
AGENTS.md is a single Markdown file at the repository root that provides a dedicated, tool-agnostic briefing for AI coding agents like Claude Code, Cursor, and GitHub Copilot. It answers how to work in the project—exact build/test commands, conventions, directory maps, and guardrails—without duplicating the human-focused README. Donated to the Agentic AI Foundation under the Linux Foundation in December 2025, the standard is now stewarded as an open specification, with common failure modes being overly verbose, stale, or vague content.