Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
Scored daily by a customisable AI persona to surface the most relevant engineering leadership news.
Real-time LLM inference optimization, highly relevant and actionable.
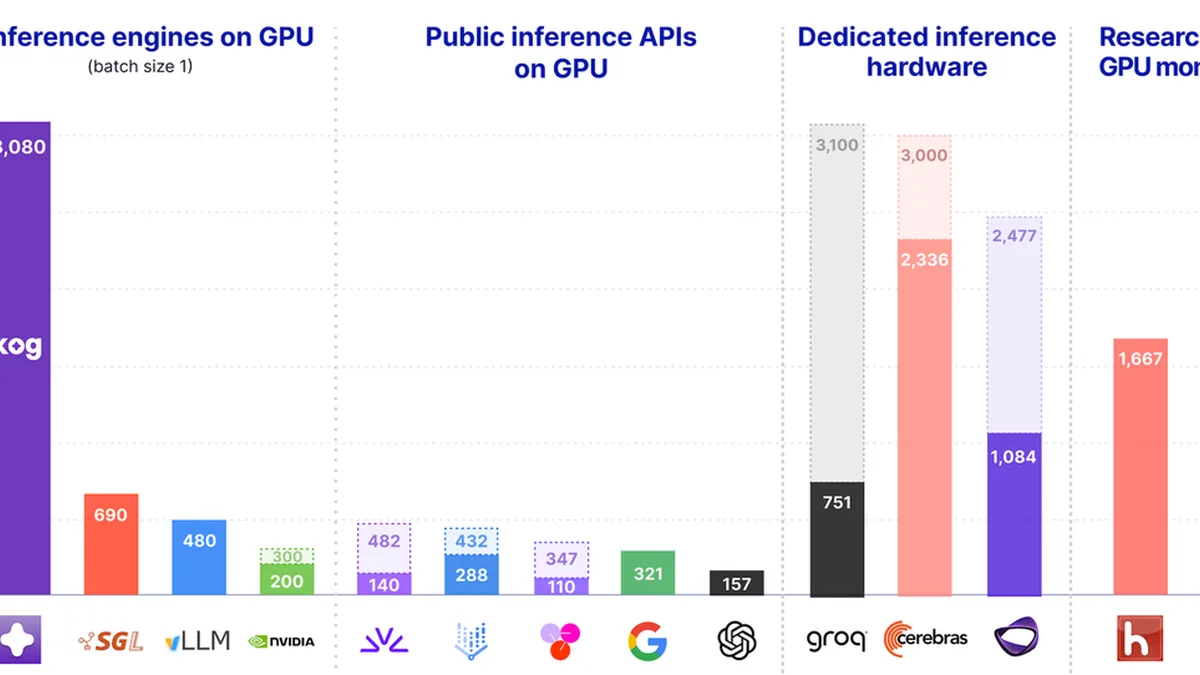
Kog achieves 3,000 tokens/s per request on standard datacenter GPUs (e.g., H200) by co-designing model architecture, runtime, and low-level GPU kernels to eliminate software bottlenecks in single-request decoding. This memory-bandwidth-bound optimization targets the sequential loops of AI agents, where 50k-token workflows drop from eight minutes to under twenty seconds, without requiring proprietary inference hardware.
- Evaluate your inference stack's single-request decode latency and consider co-designing model architecture with kernel-level optimizations to maximize memory bandwidth utilization for agent workloads.
For engineers building agentic systems or deploying LLMs on existing GPU infrastructure, this demonstrates that latency-optimized inference stacks can unlock orders-of-magnitude speedups for sequential reasoning tasks, directly impacting agent iteration speed and product feasibility.