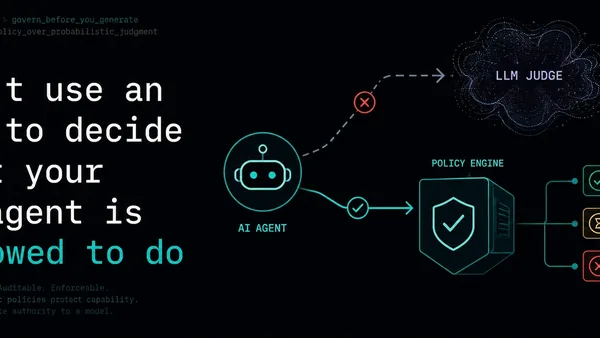
Anthropic, OpenAI, or Cursor model for your agent skills? 7 learnings from running 880 evals (including Opus 4.7)
Claude Opus 4.7 tops the baseline leaderboard at 80.5% native behavior rate, but 880 evals across nine models show that loading agent skills consistently lifts performance by +11 to +23 points, with weaker models like Haiku 4.5 gaining the most (+23.1). A cheap model with a skill (Haiku 4.5 at 84.3%) outperforms every unskilled model including Opus 4.7, suggesting skill selection now matters more than model tier for agentic coding tasks.